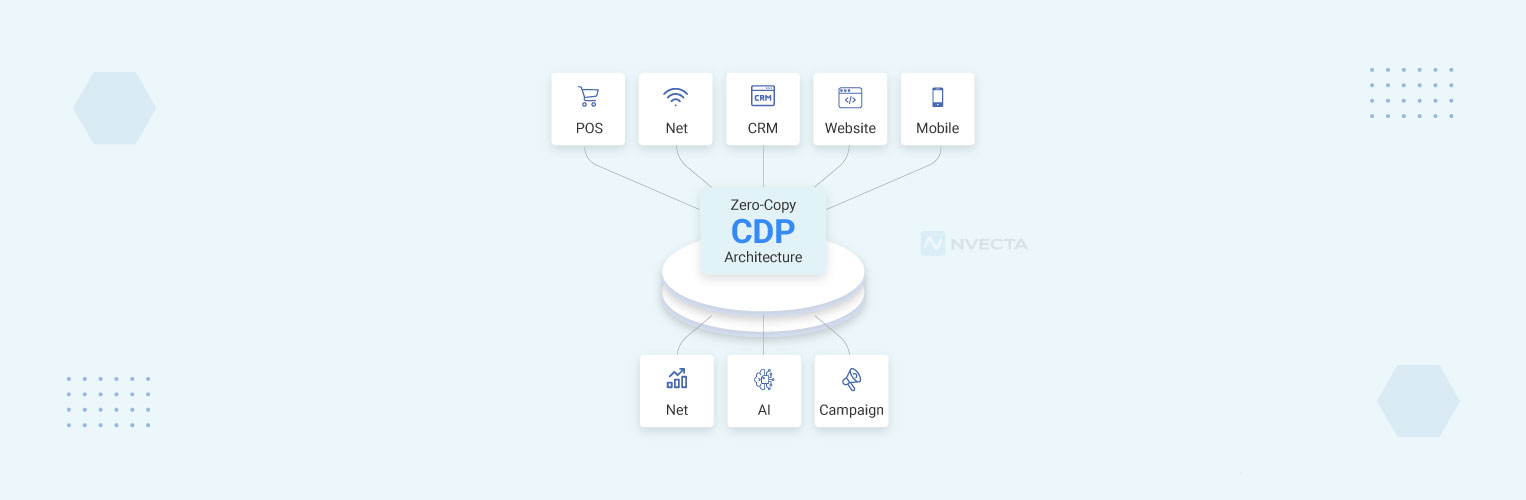
Data teams today are dealing with more data than ever, and the tools meant to help are sometimes making things harder. Most traditional CDP architectures work by pulling data from its original location, making a copy, and loading it elsewhere before anyone can use it.
That process takes time, costs money, and creates a lot of extra complexity. Zero-copy CDP architecture takes a different approach: the data stays where it is, and the platform works directly with it. Companies like NVECTA are building on this idea, helping teams get more out of their customer data platform architecture without the usual baggage of moving and duplicating data everywhere.
What Is Zero-Copy CDP Architecture?
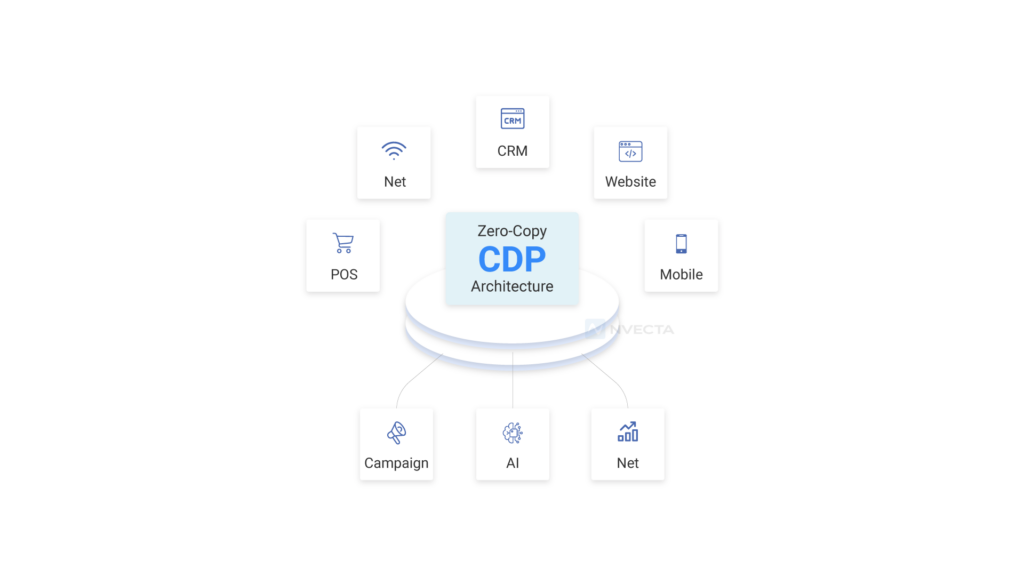
In a typical setup, a CDP pulls customer data from various sources and stores its own copy. Zero-copy architecture skips that step.
Instead of moving the data, the platform goes to where the data already lives, usually a cloud data warehouse like Snowflake, BigQuery, or Databricks, and works with it there.
No duplicate records. No extra storage. No waiting for a sync to finish.
This works because modern cloud warehouses are fast and powerful enough to handle this kind of querying at scale.
Tools built around this idea keep the storage in one place (your warehouse) and handle the logic and activation separately.
How It Differs from Traditional CDP Architecture
A traditional CDP is built around owning the data. It pulls everything in, builds its own version of the customer record, and runs everything from there. That sounds clean in theory, but in practice, it creates problems. Data goes stale because pipelines run on a schedule, the same customer record ends up in multiple places, and any upstream change risks breaking something downstream. You also end up paying to store the same data twice.
Zero-copy works differently. Your warehouse holds the data. The CDP connects to it, builds the required logic, and sends results wherever they need to go. Nothing is duplicated. Your warehouse stays the one source of truth.
Here is how the two approaches compare:
| Traditional CDP | Zero-Copy CDP | |
| Data Storage | Owns a separate copy | Stays in your warehouse |
| Data Freshness | Delayed by pipeline sync | Real-time |
| Storage Cost | Dual storage costs | Single storage layer |
| Governance | Separate rules required | Inherits warehouse policies |
| Schema Changes | Can break pipelines | Picked up directly |
| Identity Resolution | Handled internally | Built in the warehouse |
Use Cases
This is not just an architectural preference. It changes what is actually possible for data teams.
Real-Time Personalisation: Because the CDP reads live data from the warehouse, you can serve personalised content based on what a customer did minutes ago, not on what they did yesterday.
Suppression and Compliance: When a customer opts out, the update is reflected immediately across all channels. There is no delay waiting for copies to sync.
High-Cardinality Segmentation: You can build highly detailed audience segments on large datasets using the full power of your warehouse, without first reloading the data elsewhere.
Cross-Channel Attribution: All your touchpoint data sits in one place. Attribution models run against the full picture, not a subset that was copied over.
Cost-Efficient Scale: You stop paying to maintain a second copy of your data inside a CDP. Storage costs stay tied to your warehouse, not a parallel system.
Data Governance: Access controls and data masking policies live in the warehouse. They apply automatically to anything the CDP queries, so you do not have to manage separate rules in two systems.
Why Data Teams Should Care
Fewer pipelines means fewer things to fix when something goes wrong. If a schema changes upstream, the CDP picks it up directly rather than breaking on an outdated copy.
Testing new audience logic against old data is easy because everything is already in the warehouse.
For marketing and product teams, the big win is that the data is always fresh. You can act on what customers are doing right now, not hours ago.
That opens up things like in-session personalisation and catching churn signals before it is too late.
On the cost side, removing the duplicate storage layer and the pipelines needed to maintain it adds up—especially as your data grows and you’re trying to keep customer journeys consistent across systems.
Challenges to Consider
This approach is not perfect for every situation. If you need very fast query responses, warehouse latency can be a challenge. Caching and pre-computed results help a lot here, but it is worth thinking through.
Identity resolution also needs a bit more planning. In a traditional CDP, the platform handles that internally.
In a zero-copy setup, your team needs to build and maintain the identity graph in the warehouse itself, or use a service that writes results back there.
Not every downstream tool supports the connection patterns used by zero-copy CDPs, so it is worth checking compatibility with your existing stack.
None of these is a dealbreaker. The tooling around this approach has improved significantly, and most teams with a modern warehouse are closer to being ready than they think.
How NVECTA Approaches Zero-Copy CDP Architecture
NVECTA builds its CDP architecture around the idea that your warehouse should stay in control of the data.
Rather than pulling everything into a separate system, NVECTA connects directly to your warehouse, lets you build audiences and run identity resolution there, and handles the activation layer on top.
You get a CDP that fits into the stack you already have, follows the governance rules you already set, and does not charge you to store a second copy of your data.
For teams that have put real work into building a clean data warehouse, NVECTA works with that investment rather than around it.
FaQs
Is zero-copy CDP architecture only for large enterprises?
No. The savings are bigger at scale, but the simplicity benefits apply to teams of any size. If you already use a cloud warehouse like Snowflake, BigQuery, Databricks, or Redshift, you have what you need to get started.
Does zero-copy mean the CDP stores nothing at all?
Not exactly. A zero-copy CDP still stores items such as audience definitions, activation rules, and job history. It does not store copies of your actual customer records. The data itself stays in your warehouse.
How does identity resolution work in this setup?
Identity resolution happens in the warehouse. Your team builds and maintains the identity graph there, or you use a tool that writes resolved identities back to the warehouse. The CDP then reads from that graph as it would from any other table.
What about query speed compared to a traditional CDP?
For most use cases, the difference is not noticeable. When caching is in place, warehouse queries return results fast enough for real-time needs. Techniques such as materialised views and pre-computed segments further reduce latency for time-sensitive workflows.