If you’ve ever sat in a room where marketers and data engineers are trying to agree on a single platform strategy, you already know the tension. The debate around CDP vs Data Lake is one of the most common and most misunderstood conversations happening in data-driven organisations today.
As a CDP, NVECTA is built specifically to solve the customer data activation side of this equation. But understanding where a CDP ends and a Data Lake begins is key to building the right stack. This guide breaks down what each solution actually does, where they differ, and how to choose the right one for your goals.
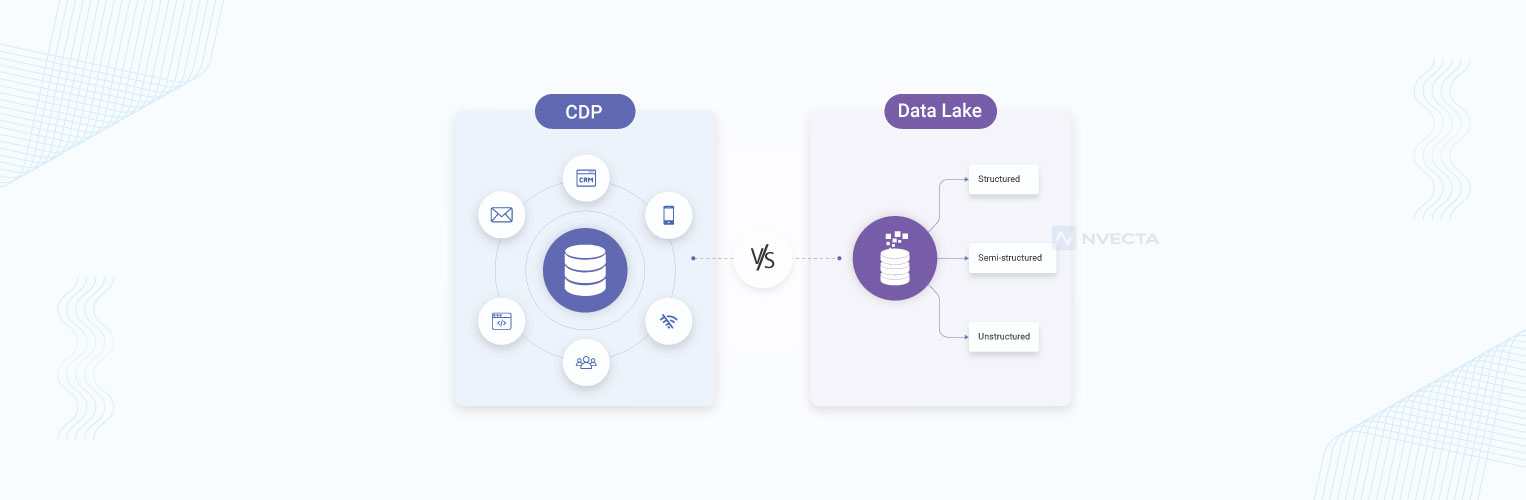
What is a Customer Data Platform (CDP)?
A customer data platform is a packaged software solution that collects, unifies, and activates customer data from multiple sources, creating a single, persistent customer profile that marketing, sales, and customer success teams can act on in real time.
CDPs are built with the business user in mind. They connect to touchpoints like your website, CRM, email platform, mobile app, and ad channels, then stitch all that data together around a single customer identity.
The result is a 360-degree view of each customer that’s accessible without needing SQL skills or a data engineering team.
Key characteristics of a CDP:
- Identity resolution and customer profile unification
- Real-time data ingestion and activation
- Pre-built integrations with marketing and sales tools
- Designed for non-technical users
- Focused on first-party customer data
Popular CDP platforms include NVECTA, Segment, Salesforce Data Cloud, mParticle, and Bloomreach.
What Is a Data Lake?
A Data Lake is a centralised repository, typically cloud-based, that stores raw, unstructured, semi-structured, and structured data at a massive scale.
Unlike a CDP, a Data Lake doesn’t impose a schema on data when it’s written. You dump everything in, and structure it later when you’re ready to query or analyse it.
Data Lakes are an engineering-led infrastructure.
They’re designed to handle enormous volumes of data logs, clickstreams, IoT signals, transaction records, media files, and serve as the foundation for analytics, machine learning, and business intelligence pipelines.
Key characteristics of a Data Lake:
- Stores raw data in its native format
- Supports structured, semi-structured, and unstructured data
- Schema-on-read approach (not schema-on-write)
- Requires data engineering expertise to manage and query
- Serves data science, ML, and BI use cases
Common Data Lake technologies include AWS S3 + Glue, Azure Data Lake Storage, Google Cloud Storage, and Databricks.
CDP vs Data Lake: Head-to-Head Comparison
| Dimension | CDP | Data Lake |
|---|---|---|
| Primary User | Marketers, CX teams | Data engineers, data scientists |
| Data Type | Customer behavioural & transactional data | Any type of data at any scale |
| Structure | Structured, profile-centric | Raw, schema-on-read |
| Activation | Built-in (push to channels) | Requires additional tooling |
| Real-Time Capability | Yes, native | Possible, but complex to implement |
| Identity Resolution | Core feature | Not included |
| Setup Complexity | Moderate (SaaS, faster) | High (requires engineering) |
| Cost Model | Per profile/event | Storage + compute |
| Governance & Compliance | Often built-in (GDPR, CCPA) | Requires custom implementation |
Key Differences Explained
1. Purpose and Design Philosophy
A CDP is purpose-built for customer data activation. Every feature—from identity resolution to segmentation and journey orchestration supports the broader goal of enabling more effective use within customer engagement platforms, helping teams better understand and engage their customers.
A Data Lake is purpose-built for data storage and flexibility. It’s infrastructure, not a product. It gives you the raw material to build almost anything, but it doesn’t do anything by itself.
2. Who Owns It
CDPs are typically owned by marketing operations or RevOps teams. They’re designed to be used without writing a single line of code.
Data Lakes are owned and maintained by data engineering or platform teams. Using them meaningfully requires expertise in tools like Spark, dbt, Presto, or Athena.
3. Data Freshness and Activation Speed
CDPs shine at real-time and near-real-time use cases, triggering a personalised email seconds after a cart abandonment, or updating an ad audience the moment a customer converts.
Data Lakes are excellent for historical analysis and batch processing, but typically introduce latency.
While real-time streaming (via Kafka, Kinesis, etc.) is possible on a Data Lake, it requires significantly more engineering effort.
4. Identity and Profile Management
Customer identity resolution is at the heart of every CDP. It merges anonymous and known profiles, resolves cross-device behaviour, and maintains a persistent customer record.
Data Lakes have no native concept of identity. Building customer profiles on a Data Lake is absolutely possible, but it requires custom engineering, matching logic, and ongoing maintenance.
5. Compliance and Data Governance
CDPs typically come with built-in consent management, data deletion workflows, and compliance tooling aligned with GDPR, CCPA, and similar regulations.
Data Lakes require you to implement governance, access controls, and compliance workflows from scratch, which adds time and cost.
When to Use a CDP
A CDP is the right choice when:
- You need to personalise customer experiences at scale across email, web, mobile, and paid channels without a heavy engineering lift.
- Your marketing and CX teams need direct access to customer data without depending on a data team for every segment or report.
- Identity resolution is a priority when dealing with fragmented data across devices, channels, and touchpoints.
- Time-to-value matters; you need to go from data to campaign in days, not months.
- Compliance is a concern; you need a GDPR/CCPA-ready tooling out of the box.
Ideal for: E-commerce brands, subscription businesses, B2C companies with high customer interaction volume, and any organisation running omnichannel marketing programs.
When to Use a Data Lake
A Data Lake is the right choice when:
- You’re dealing with massive, diverse data volumes, IoT, logs, clickstreams, media, and financial transactions that go far beyond customer profiles.
- Data science and ML are core to your business, your team is building models, running experiments, and needs raw, unfiltered data to work with.
- You need a flexible, long-term data foundation, one that can serve analytics, BI, reporting, and future use cases you haven’t defined yet.
- You have a mature data engineering team capable of building and maintaining the necessary pipelines and tooling.
- Cost efficiency at scale is a priority. Storing petabytes of raw data is far cheaper in a Data Lake than in a CDP.
Ideal for: Enterprise organisations, data-heavy industries (fintech, healthcare, media), and companies with dedicated data platform teams.
Can You Use Both? (Yes, and Many Companies Do)
CDP vs Data Lake isn’t always an either/or decision. Many mature data organisations run both, and for good reason.
A common architecture looks like this:
- Data Lake serves as the central data repository storing raw event data, historical records, product data, and third-party datasets.
- CDP sits on top of (or alongside) the Data Lake, pulling in refined customer data and activating it across marketing channels.
Some modern CDPs even offer reverse ETL capabilities or direct warehouse.
lake integrations, narrowing the gap between the two—especially as explored in Reverse ETL vs CDP, where the distinctions continue to blur with evolving data architectures.
Platforms like Segment Unify, RudderStack, and Hightouch are increasingly blurring the lines.
The right architecture depends on your team’s maturity, your use cases, and your budget.
Common Mistakes to Avoid
Buying a CDP expecting it to replace your data infrastructure. A CDP is not a data warehouse or a data lake. It handles customer data activation, not enterprise analytics or ML.
Building a Data Lake and assuming your marketers can use it. They can’t, without significant tooling on top. A lake without activation is an island.
Choosing based on vendor hype. Both CDPs and Data Lakes have enthusiastic vendor communities. Anchor your decision in your actual use cases, team capabilities, and roadmap.
Final Thoughts
The CDP vs Data Lake debate ultimately comes down to who needs the data and what they need to do with it.
If your goal is to activate customer data faster, personalise at scale, and give business teams direct access, a CDP wins.
If your goal is to build a flexible, scalable data foundation that supports analytics, ML, and a wide range of use cases, a Data Lake is the right investment.
And if you’re a growing enterprise with both needs, a hybrid approach is often the most powerful path forward.
Why NVECTA
If a CDP is the right fit for your business, NVECTA is built to make customer data work harder for your team. NVECTA brings together real-time identity resolution, unified customer profiles, and seamless activation across your marketing and sales channels, all without the heavy engineering overhead.
Whether you’re moving away from fragmented data tools or looking to complement your existing Data Lake with a powerful activation layer, NVECTA gives your teams the customer intelligence they need to act fast and personalise at scale.
Ready to see NVECTA in action? Book a demo today and discover how NVECTA can unify your customer data and drive real results.
FAQ
What is the main difference between a CDP and a Data Lake?
A CDP is built to collect, unify, and activate customer data for marketing and CX teams, with no coding required. A Data Lake is an infrastructure layer that stores raw data at scale for data engineers and data scientists to process and analyse. One is about activation; the other is about storage and flexibility.
Can a Data Lake replace a CDP?
No. A Data Lake stores raw data but has no built-in identity resolution, activation workflows, or compliance tooling. To replicate even basic CDP functions on a Data Lake, you’d need significant custom engineering. They serve fundamentally different purposes.
Can a CDP replace a Data Lake?
Not for enterprise-scale analytics and ML workloads. A CDP is optimised for customer data activation, not for storing petabytes of logs, IoT signals, or media files. Companies with both needs typically run a CDP and a Data Lake in parallel.
Who typically owns a CDP vs a Data Lake?
A CDP is usually owned by marketing operations or RevOps teams and is designed for non-technical users. A Data Lake is owned and maintained by data engineering or platform teams who work with tools like Spark, dbt, Presto, or Athena.
Which is better for real-time personalisation: a CDP or a Data Lake?
A CDP is the clear choice here. CDPs are built for real-time and near-real-time activation, like triggering a personalised message seconds after a cart abandonment or updating an ad audience the moment a customer converts. Achieving the same on a Data Lake requires significant additional engineering.
Do I need both a CDP and a Data Lake?
Many mature organisations run both. A common setup has the Data Lake handling raw storage and historical data, while the CDP sits on top to activate refined customer data across marketing channels. Whether you need both depends on your team’s size, technical maturity, and use cases.